
A brief history lesson of how we got here.
GitOps is a practice that uses Git (source control) as the source of truth for your codified infrastructure. Coupled with a way to sync your stack’s current state against this source code, your system will continuously converge to what has been set as its desired state. Much like common software delivery practices, the ability to deploy changes starts with the pull request.
A couple of years ago, Weaveworks developed GitOps, but the concept of managing your infrastructure with code has been around for decades. Store that code in a git repository, and you have an idea that just makes sense.
As of late, I’ve been noticing GitOps gaining a lot more attention. I believe it’s because the people that have been dealing with the same system-related problems for years have compiled all of our best practices, and have built the tech that has made it possible for us common-folk to declare an entire stack to provision continuously. With ease!
To understand why this is important, you will need a little context.
Back in the day, back when I was patching enterprise PCs for Y2K via 3.5″ floppy disk, the systems engineers were codifying infrastructure as much as they could with scripts and Windows SMS Server 2.0.
Years later, when it was finally my turn to have a go at codifying a serving infrastructure, operations were still managed by in house experts in their own data centers; from the beeps and bops, from the edge to the core.
I think the year was 2007 or 2008. Many of us were responsible for managing a company’s infrastructure. The cutting edge thing to do back then was to migrate your shell scripts to a configuration management tool so you could configure segments of servers in bulk. We were adopting the Sprint for the very first time too, so trying to understand how to “point” the effort of racking and stacking was confusing as hell. Then it was like, who installs Apache? The latest config management tool was the first step in being able to give some sort of proper estimate alongside the software development efforts. New teams started to form and once again I was lucky to be in the thick of it.
I remember having to automate the provisioning of a 9 node Hadoop cluster using Puppet. That’s going be infinite points because I don’t know what is a Hadoop. I know Hadouken.
HADOUKEN!
It was rough at first, but what was once a fierce war, suddenly became this beautiful partnership. A truce was declared and the DevOps paradigm has since become the basic standard. Scale has been achieved, the “cloud” is GA, and XaaS solutions are everywhere.
In regards to building and managing complex systems, I’ve marked those events above as game-changing shifts because of how trusted and significant each of those layers of abstraction has become.
Without these layers, imagine having to guess how many physical servers you need to budget for next year based on a product that isn’t even built yet. Imagine seeing traffic spike up, only to remedy the situation by purchasing a new server, getting it to the data center, physically installing it in the rack, powering it on, configuring it (OS & network), only to then deploy your proprietary and non-proprietary software, configuring those, and then adding it to your serving stack, only after someone has certified it. I’m probably missing a few steps, but yea, we used to do this, under pressure. Fry’s Electronics was our best friend.
The only fries I think about now
Our latest shift has been running our apps and services in containers. In just a few years, Docker, in particular, went from a single machine-bound development tool to your standard artifact. A few days before writing this, Kubernetes 1.18, was released. As with each release before this one, Kubernetes moves closer to securing its own position as a game-changer. If you combine Docker & Kubernetes with these other layers of abstraction, it makes it possible for me to push a button and add more serving capacity within seconds, all from my phone.
This is where we are today. For the new, welcome. Things are way nicer than they were back in the day. For those that remain parallel with the cutting edge, our time is finally here.
Here is where GitOps comes in.
To this day, I believe if you can continuously deliver your entire system on-demand, from the servers to the software, you should be put in a category of the Few and Distinguished. It could be done, even back then, but with what they used to call “bubble gum and duct tape”.
With newer toolsets now aligning with best practices, what was once an extremely difficult and tedious effort for some, can now be realized fairly easily with an accepted standardized implementation.
So if Kubernetes is now the standard, and git is a standard, what’s with the fancy name? Why do I need to change any of my current processes?
If you have a solid version of the 3 P’s, Policies and Processes you can Practice, then you are probably already doing some form of this.
Here’s a little bit more info that you can diff against.
- Kubernetes is mostly declarative so we should take advantage of this. Along with K8S, today’s tools leverage easier-to-understand YAML to configure your systems.
- The pull request is used to trigger your update. You get the benefit of a peer review and existing change management processes.
- There is an automated delivery system that is responsible for applying the change. Manual changes are unnecessary and bad practice, especially if people are logging into servers.
- No kubectl. RBAC for user-level access control isn’t trivial. (Check out the AirwaveTech article on how to help with this)
- The desired state of your entire stack is housed in source code. Various offerings of git allow extensibility for building custom solutions.
- Gain new abilities: Predictability, Repeatability, Rapid Recoverability. This is what happens when you have the 3Ps.
Push VS Pull. Are you manually pushing a button or is the system automatically applying the changes? Think of this as being analogous to continuous delivery VS continuous deployment, with pull equating to automatically deploying software.
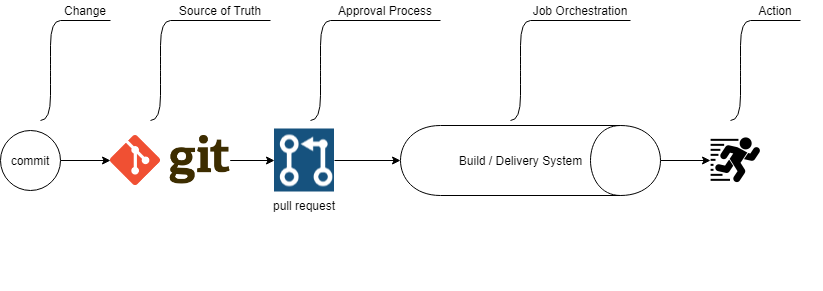
a very simplified GitOps Pipeline
There is a difference between configuring the underlying Host/VM, configuring Kubernetes, and deploying an app. How does this diagram and GitOps apply?
What isn’t yet standard, or even simplified for that matter, is our CI/CD/Job Orchestrator solution. In the diagram above, we have a generic pipeline because everyone’s solution will differ depending on what you are trying to do.
GitOps could be applied to the following scenarios:
- Host / VM changes
- Kubernetes changes (what most people think of when you say GitOps)
- Software deployments to Kubernetes
As long as you can sync from git and then coordinate the automated provisioning efforts at each layer of your stack, you will have achieved your goal. If you are using the latest tools, I’m pretty sure you are probably just a few steps away from getting there. I will cover some of those tools in a future post.
Okay, so GitOps is more of a principle?
Kind of. In most cases, you’re probably adhering to some form of change control already. If you are like me, you might be managing a push system, where once changes are approved they are applied manually. That’s okay, but it can be daunting, and sometimes scary.
GitOps takes what we’re doing one step further by automatically converging changes as soon as they are approved. This way your systems are constantly in line with your latest and greatest.
To sum it up…
Whether you are managing Kubernetes itself, the layers above, or below it, it makes sense to set your desired state in a persisted place. Some folks used to do it with scripts and Cron, others used to keep it in a DB. Today, it’s git and YAML. Regardless of how you do it, with a system that can be as complex as Kubernetes you won’t want ad-hoc changes performed on the fly anyway. You want to make sure you are practicing some form of change control. If you are already using git, why reinvent the wheel?
Everyone thinks of the worst-case scenario, but have you thought about the pain and fear you incur on a day to day basis from just having to do your job? Sometimes it’s so bad, you can’t even do your job. This doesn’t happen overnight but builds over time. The nightmare situations happen when things aren’t broken, per se, but when one small change causes a chain reaction of chaos. Then, things become broken and nobody really knows why.
If you find yourself struggling to control your environment, it might be best to invest in some form of organization effort, even if it’s not particularly GitOps, to bring some sanity to our ever-evolving roles.
If you need assistance getting your infrastructure code in order, please feel free to reach out to us at https://www.airwavetech.io/contact-us